
Going through my old records, I found this article which I co-wrote with my friend, Christoph Schmaltz. The content is still very much relevant, so I decided to repost it.
Bridging data silos – An overview of integrating systems of record and systems of engagement
Summary
Enterprise applications must effectively connect employees. This article explores integrating social software and legacy systems, covering use cases, integration approaches, technical challenges, and the future of integration frameworks.
2) Integration from a user perspective
2.1. Application Linking and Embedding
2.2 Widget Based Portal Applications
3 Integration from a technical perspective
4) Outlook / Where are we going?
1) Introduction
We live in a hyper-connected world. Modern technology enables us to call friends on the other side of the planet or connect with total strangers on the World Wide Web (WWW). We have access to more information than we ever wished for and can instigate change we never dreamed of.
However, this picture looks very different in the enterprise. Over years, businesses have heavily invested in software applications to optimise business processes. Often, each of these applications represent a data silo, as most of them are only insufficiently connected – if at all. Furthermore, in the past decade a new breed of software application has entered the enterprise, promising organisations to build more reliable and useful knowledge networks within companies by connecting employees and thus knowledge in a more effective way. Ironically however, rather than breaking down information silos they create new ones.
Thus, organisations and software vendors need to find ways of integrating a range of enterprise applications that are both effective for users and cost-efficient for organisations.
1.1 Systems of Record
Without a doubt, information technology has transformed the way businesses operate. So-called Systems of Record (SoR) “capture every dimension of our commercial landscape, from financial transactions to human resources to order processing to inventory management to customer relationship management to supply chain management to product lifecycle management […]” (Link to Moore p3). In a sense, SoR can be characterised as the plumbing network as they form a core part of any business infrastructure. As Dion Hinchcliffe points out “it’s safe to say that most firms would go out of business without the data within and automated capabilities of their systems of record.” (Link to Dions Blog Post).
Some examples of Systems of Record include: Enterprise Resource Planning systems (ERP), Customer Relationship Management systems (CRM) and Supply Chain Management systems (SCM). SoR have become more complex and powerful and have helped to eradicate inefficiencies in business processes. However, the very nature of these systems has not changed. According to Moore, they focus on transactions, employ a command and control governance, hold facts and dates, are the single source of truth and excel in accuracy and completeness. (Link to Moore p5) It is only recently that vendors of SoR have started to incorporate new interaction modes and allow users to discuss and collaborate around transactional data (e.g. Salesforce Chatter (CRM), Microsoft SharePoint (DMS)).
1.2 Systems of Engagement
If Systems of Record can be characterised as the plumbing network, Systems of Engagement (SoE) are the control centre. Within the control centre, employees monitor the input and output of the plumbing network. They can flag issues, identify and locate experts, discuss and resolve issues in a collaborative process and document the learnings for the future by using Systems of Engagement.
Systems of Engagement are primarily known as social software. In an article in 2006, Prof. Andrew McAfee introduced the SLATES framework (LINK) to categorise social software. His framework provides a good foundation but, however, it has become dated over time. Hence, the authors of this article have extended the original framework to reflect recent developments in social software.
Search: searching content by keyword; Today, social search plays a critical role in finding the right content, given the deluge of information available. Social search means that search results are prioritised or even filtered based on users’ own actions or their network’s actions. However, this comes with its own challenges. (econsultancy link)
Links: number of incoming links decides on authority; Today, authority of content is measured not only by the number of incoming links but also direct and indirect actions from users. This can include applying certain metadata (see ‘Tags’ below) like liking, rating, sharing, viewing etc.
Authoring: creating content; Creating content is still one of the key activities enabled by social software.
Tags: tagging content; Tagging content has been extended by applying additional metadata through liking, favoriting, sharing, rating, viewing and other actions. These actions allow content to be structured and searched in novel ways.
Extension: recommending content or users based on actions;
Signals: allowing people to subscribe to users or content with RSS feeds; This category has probably seen the most dramatic change since McAfee introduced his framework. Initially, RSS was seen as the underlying notification system of the Web 2.0. Today, however, it has been relegated to a niche existence. (Techcrunch article) Rather than relying on RSS feeds, people now receive curated information streams from their connections and from the connections of their connections using microblogging. Furthermore, signals now also include notifications triggered by actions other than publishing content, e.g. liking, sharing, rating and others.
Whilst McAfee applied the above framework to enterprise social software (Enterprise 2.0), (Link to McAfee’s article) it equally applies to Web 2.0 tools (often referred to as Social Media tools) which have enabled a new interaction paradigm on the Web. The main differences are the context in which these enterprise and consumer tools are used and additional functionality for security, compliance, data ownership and retention and permissions of Enterprise 2.0 tools.
In recent years, a raft of social software categories have emerged. There are wikis, blogs, RSS aggregation and management systems, microblogging platforms, social networks and others (LINK to BACK/KOCH). As work processes have become ever more complex though, it is rare that one tool category (e.g. wiki) is sufficient. Indeed, among systems of engagement, certain tools have evolved from best-of-breed to fully-fledged social software suites. Examples include: Jive (originally discussion forums), Socialtext and Confluence (originally wiki) and Yammer (originally microblogging)).
However, even software suites have limitations and will eventually need to integrate with other Systems of Record and Systems of Engagement.
2) Integration from a user perspective
New Systems of Engagement will not replace Systems of Record (AIIM, tcgAdvisors: A “Future History” of Content Management, p16). Instead, SoE sit on top of SoR or in our analogy: The control center sits on top of the plumbing network. Before looking at the technical ramifications of different integration approaches in Section 3, we look at the approaches from a user perspective first. To help us we have listed some common use cases that we have come across in actual implementations below. We will look at these when we talk about the different integration approaches from a user perspective in this section.
1) Bridging internal and external conversations
The Web 2.0 enables everyone to participate in conversations. Some of these public conversations can be relevant and interesting to businesses. Organisations need to find ways to bridge their internal world with the external world and vice versa.
2) Discussing client opportunities
Customer Relationship Management systems (CRM) have been around for some time. However, often they are relegated to data stores, which are liked by managers but hated by users due to their complexity and the perceived limited value to them. It is important to integrate CRM data and to make it available in the right context where it can be seen and enhanced by others.
3) Current Awareness
Especially in knowledge intensive industries like professional services, it is critical for knowledge workers to keep abreast of developments in the market that could have an impact on clients. New applications like RSS feed management systems enable users to monitor hundreds of news sources. If this is done in a joined-up way, organisations could save lots of time and money. However, this requires the integration of such news tools with other applications.
4) Content collaboration:
Regardless of the industry and the role, content collaboration is a critical activity in the knowledge economy. Content collaboration used to take place only in structured format (documents). These days unstructured format like wikis are proving more and more popular due to the shortcomings of document collaboration. However, applications need to be integrated into users’ workflows and hence into systems used on a daily basis, no matter where content collaboration takes place.
2.1. Application Linking and Embedding
The easiest and most straightforward way of connecting different web-based applications is by using hyperlinks or embedding iframes. This approach is mentioned here only for completeness and will not be discussed in detail, as it is not regarded a proper integration where data is exchanged between different systems.
2.2 Widget Based Portal Applications
In this integration approach, the application interface is composed of multiple widgets which display contents from other applications. Widgets are fully-fledged client side applications which are authored using technologies like HTML and JavaScript. Traditional widget based portal applications do not allow for inter-widget communication, and the contents within individual widget are separate islands of information displaying data out of context. Most importantly, although the user is exposed to data coming from other systems, the benefit is limited as the user cannot interact with the data.
The most prominent example on the Internet of this approach is iGoogle (Link), which allows users to build their own dashboard and select from a myriad of widgets. In an enterprise setting, such dashboard can often be found on corporate Intranets or some other portal application. The implementation of the use cases mentioned above is fairly straightforward. A user selects a number of widgets and configures them according to their needs or an administrator could do the same for an entire group.

Figure XXX: Example of a widget based portal application with a number of independent widgets
From a user perspective the use cases mentioned in the beginning of the chapter could be implemented in the following way:
1) Bridging internal and external conversations
The user creates a widget that pulls in public Twitter messages from a particular user to monitor his activity. One of those messages is picked up by a colleague seeing the widget. He sends an email to other colleagues linking to the tweet. An email discussion follows.
2) Discussing client opportunities
An administrator has created a widget for a practice group at a law firm that pulls in data on won and lost opportunities from the organisation’s Customer Relationship Management system. One of the firm’s partners searches the Portal for information on a specific client. Since the CRM data is not indexed in the widget based portal approach he only finds content on the client that was created on the Portal.
3) Current Awareness
A professional support lawyer (PSL) has created a widget that pulls in a feed from a particular news source (e.g. BBC News). The PSL clicks on one of the news items and is taken to the article on the BBC website. He would like to share it but does not want to send an email with the URL and does not have other possibilities to easily share the article. He gives up and ends up not sharing it.
4) Content Collaboration
The user creates a widget that pulls in folders and documents relevant to his team and which are stored in the company’s Document Management System. When clicking on the document, it is opened in a desktop application. Once saved the user sends an email to colleagues that he updated the document. An email chain starts in which changes on the document are discussed.
Advantages
This approach certainly helps to create awareness of what is happening in different systems, both SoR and SoE. Information is coming to the user rather than them having to fetch it manually. From a technical perspective this approach does not require an intermediate storage of information which makes it a less costly approach. The content is directly displayed in real time from the underlying applications. Technically Java Applets or Web Services using Html and JavaScript can be used to achieve this goal as discussed in section 3.1.
Disadvantages
Unfortunately, there is a trade-off between simplicity and benefits. From a pure User Experience (UX) perspective, the dashboard can quickly become overloaded with widgets full of unrelated data streams. More critical, is the lack of integrated search and missing possibility of taking action on top of the data presented in the widgets. In the end, the portal application is a pure presentation layer with windows that provide a glimpse into other systems. Due to its limitations we expect this integration approach to be overtaken by the next generation of integration systems like content streams.
2.3 Content Streams
This is an enhancement to the widget approach. The content from underlying applications (both SoR and SoE) is aggregated and displayed in a continuous stream. Within a content stream, the actions or settings are associated with individual content items in addition to the content stream itself. Like the widget approach, one can alter the number of contents displayed for the content stream and also alter the order. Individual content items can have actions associated with them like liking or bookmarking of a content item. This approach allows the user to view the content and to perform actions on the item.
The Content streams use web services to integrate contents from multiple applications as discussed in the standardised integration methodology (Link) above. As the contents are to be aggregated from multiple application on a frequent basis, it is essential to use technologies like message bus or timer service to obtain contents and store them in a centralised location for immediate access.
Facebook which helped this approach to go mainstream, introduced its news feed in September 2006 and has even been granted a patent (Link Patent) for it. Whilst in the beginning, the feed included only updates from a user’s network, it now also aggregates activity from third-party applications that users are using. In the enterprise, more and more software vendors have started incorporating content streams. Some of these are internal to the application, i.e. they only aggregate activity generated within the application (e.g. Confluence). Other vendors have started placing the content stream at the very heart of their applications. These applications become a social layer (IBM Diagram Section 3.1) that sit on top of SoR and SoE and aggregate activity generated in those systems. Examples are Socialtext, Yammer, Tibbr. Besides creating awareness, users can then also start to take actions on these items like creating a discussion, sharing, tagging, bookmarking or liking it. Other actions are possible depending on the content item.
Figure XXX shows an exemplary content stream that integrates with underlying applications and aggregates activity generated in those.

Figure XXX: Example of a content stream that integrates with underlying applications and aggregates activity generated by those applications.
From a user perspective the use cases mentioned in the beginning of the chapter could be implemented in the following way:
1) Bridging internal and external conversations
An auditor uses Twitter to stay connected with clients among others. He stumbles upon an interesting tweet, which he would like to alert colleagues to. Rather than sending an email or going to the group space on the corporate Intranet, he adds a particular hashtag to the tweet. The tweet is shared seamlessly with the group because the system knows that the user has the permission to publish tweets in the group and the hashtag defines the location of the sharing. Within the content stream, other users can take actions like commenting, liking or bookmarking to read the tweet and discussion later.
2) Discussing client opportunities
A partner at a law firm went to see a client. He updates the company’s Customer Relationship Management system (CRM) and adds some notes. This activity is automatically shared with the relevant Practice Group on the corporate Intranet. Another partner sees the activity and can respond to it on the Intranet or by other means.
3) Current Awareness
A professional support lawyer (PSL) is tasked to monitor hundreds of news sources on a daily basis. Rather than subscribing to email alerts or browsing all those sources, she uses an RSS aggregator. She clips the most relevant news stories and adds a short comment for each. These clippings appear seamlessly in the activity stream of a community on the corporate Intranet where other users can take actions like commenting, searching or bookmarking to read it later.
4) Content collaboration:
An HR professional and her team are collaboratively working on a new company policy document. The document is stored in the company’s Document Management System (DMS). She accesses the document through the DMS and edits it. When done, she saves the latest version back to the system. This generates an activity that is published in the content stream of her HR group.
Advantages
One of the most important advantages to this approach is that activity from both SoR and SoE is aggregated in one single content stream, offering a unified user experience. The stream enables the user to quickly skim relevant activities and through its serendipitous nature to discover items they may have missed. Due to the lack of alternatives, people have come to abuse their email inbox as a news aggregator and are now overwhelmed by the amount of emails received. However, most emails are for awareness purposes and should be consumed in a different format and system like an activity stream (Link to Luis Suarez).
The second most important advantage is the ability to take actions on the aggregated items. Whilst the widget approach creates awareness, this approach takes it a step further enabling users to socialise data from other systems therefore enriching and enhancing it.
Disadvantages
Content streams can be overwhelming and could potentially result in the same failure as email inboxes did (Link to Gartner). Filters can help to reduce the noise and manage streams in more effective ways. More importantly, software vendors have acknowledged that not all activity within content streams has the same importance. Certain activity is intentionally shared in content streams by users, for example bookmarks, news clippings, tweets, whilst other activity is generated from systems for example, if a user created a wiki page or updated a document. In particular, system generated updates can lead to noise and redundancy in the content stream. On the Internet, Facebook started separating these items and introduced a separate stream which lists mainly activity generated by third-party applications. In the enterprise, Yammer has started doing the same. Alan Lepofsky has written more about the shortcomings of activity streams and how to improve them. (link to his blog post).
The Implementation approach is complex compared to the other approaches discussed above, as an intermediate content storage is required to aggregate contents from multiple applications. The aggregation is carried out using a message queue system, so that contents are not missed out. The activity stream contents are not real time but near real time. This means that the aggregation engine has to operate in the background to fetch contents and then place it in the activity store. (see Section 3.1)
3 Integration from a technical perspective
In the following section, we will discuss Integration Methodologies, Integration Patterns and Integration Challenges.
3.1 Integration Methodologies
1) Database Level Integration
For a long time, database level data integration has been the most common way of consuming data from various applications. This approach partially worked within organisations, where the structure and access to database level integration was possible, and security was not a concern. However, this approach becomes increasingly complex when one has to consume information from applications that are present on different networks and organisations.
2) Middleware Architecture (pp 39 – 62 Link to Essential Software Architecture)
Realising the need for information flow, large software vendors developed multiple technologies like DCOM, CORBA and others to meet the integration needs of remote applications. These methodologies were complex and resulted in vendor lock-in, as it was very difficult for these technologies to communicate with each other.
The Middleware Architecture refers to a set of software applications which have a middle application layer between the application interface and underlying application servers like the database servers.
Business applications are distributed not only within a single network. They can span multiple networks across the globe. Client server based communication methodologies (e.g. Distributed Objects) were developed to manage communication between these geographically distributed applications.
Distributed Objects
This architecture has been in use since 1990. The best known example is CORBA which allows communication between client and server using Interface Definition Language (IDL).

Figure 1: Diagram describes communication between distributed objects residing in different machines (http://en.wikipedia.org/wiki/Distributed_object)
The server process must create an instance of the server and make it callable through the Object Request Broker (ORB). A client process can initialise a client ORB and get a reference to the server, and hence can call methods on the server. CORBA is a synchronous communication mechanism.
Message Oriented Middleware
Message Oriented Middleware (MOM) is one of the key technologies used for building large scale enterprise systems. Individual enterprise applications can use the services from other systems by placing a queue between the sender and the receiver. MOM is an asynchronous form of communication technology.

Figure 2: Diagram depicting Messaging through Message Oriented Middleware. (Link)
3) Service Oriented Architecture (SOA) (pp 65 – 80 Essential Software Architecture)
Taking into account the growing need for information exchange, vendors came up with web services as the glue to bridge the information silo. XML-RPC, SOAP and REST are some of the technologies used for web services. To standardise the communication methodology XML was developed to allow vendor neutral communication between applications. Vendors can expose their applications’ capability based on a web services interface. Web services based communication allows applications to act as black box of information. There is an idea of Producer and Consumer to allow communication. The Producer provides the resources or information. The Consumer can consume the information from the Producer. e.g. Who’s Who system which allows other applications to query for users’ profile information. The Who’s who system can provide various capabilities like the list of users, details about a particular user, or the office they work in.
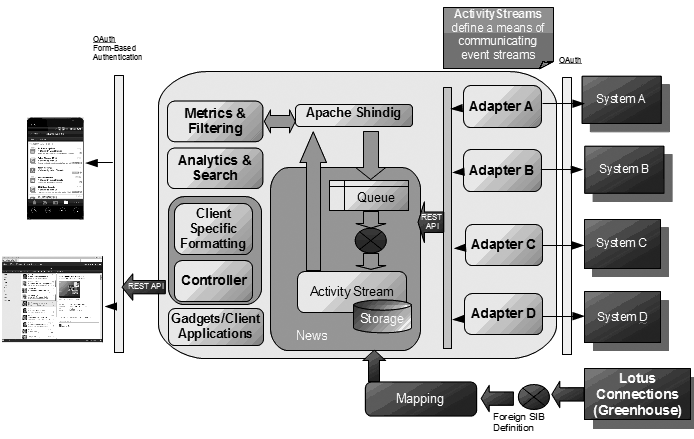
Figure 3: Diagram showing activity stream architecture using adapters for each integrated application (LINK IBM social business toolkit)
On the right hand side of the above diagram, individual adapters for each integrated application are depicted. Adapters are built specifically for the application to comply with its web services interface. For the more traditional or proprietary application, the adapter may need to integrate at a more basic level for example, database level integration or language specific API integration. Once the adapters have done their job, the contents are obtained on a regular basis using a message queue system. The message queue system stores the information into a centralised activity stream store, which is exposed out in the form of REST interface using various content filters and managers. The REST API is then used to create a lightweight website or mobile interface. This concept is also known as pace layering.
3.2 Integration Patterns
Enterprise Integration patterns provide a consistent vocabulary and visual notation to describe large-scale integration solutions across many implementation technologies such as those discussed above.
Mediation
In this integration pattern, one of the integrated applications acts as a broker between the various integrated applications. Changes to any of the integrated applications are mediated to others through this central application.
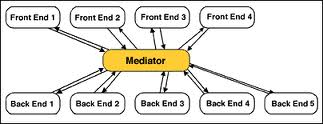
Figure 4: Mediator pattern (http://www.gofpatterns.com/design-patterns/module6/mediator-pattern-structure.php)
Federation
In this integration the system acts as the overarching facade across multiple applications. The calls to individual application functionality is passed through the federation system, and no direct call is made to the integrated application itself. For example, documents from the DMS are displayed in the federation system with any conversations around it managed in the federation layer and no direct access to the underlying DMS is required. The integration system is configured to expose only the relevant information and interfaces of the underlying applications, and performs all integrations with the underlying applications on behalf of the requester.

Figure 5: Federation Architecture (IBM http://www.ibm.com/developerworks/patterns/application/at12-runtime.html)
Both federation and mediation patterns are often used concurrently. The same integration system could be keeping multiple applications in synchronisation, whilst servicing requests from external users against these applications.
3.3 Integration Challenges
Infrastructure
Integration systems have a requirement to support multiple applications. Hence the architecture of these systems is normally rather complex. There are few essential services that are prerequisite for an integration system like enterprise search, centralised authentication, profiles, enterprise database server, message bus, web server and others. Therefore, the base architecture may require more than one physical application and server. In addition, as integration systems need to expose an API for integration, they need to be highly available and should be deployable on a distributed architecture.
Centralised Authentication and Authorisation
As indicated above, in order to support single sign-on between multiple applications, integrated frameworks use a centralised authentication system like LDAP, OpenID or Active Directory. The permissions and roles for the users could be internal to the integration platform, but they could also get delegated to the directory services. e.g Shibboleth.
Centralised Search
As contents within the integration platform are aggregated from multiple applications and sources, it is essential to build a search system which can index these contents at a centralised location. For a useful search system, the contents need to be sectioned in both structured and unstructured way, so that keywords can be used to filter contents. Tags are an unstructured way of organising contents. In addition to the content the metadata associated with the contents like the tags need to be indexed into the search system to improve findability.
Unified User Interface
Each integrated application within the integration system has a different interface: it is difficult to provide a consistent look and feel between the applications using the mediation model. In addition, a consistent navigation between the applications is a difficult goal to achieve.
Performance
It is not possible to provide real time contents from the integrated applications as the time required to execute a web service request on each interface is costly and may result in a significant performance degradation of the system. As a result, a message bus or a timer based service is used to fetch contents from underlying applications and stored in a centralised database and then accessed ‘on the fly.’
4) Where are we going?
System of Engagements will become the centre.
1) systems of record become more social / engaging. every tool will have open apis. we are now seeing vendors of system of records adding social functionality to their products. problem persists that these systems are in isolation.
serious about integration. assessing integration: http://www.alanlepofsky.net/alepofsky/alanblog.nsf/dx/integration-maturity-model
2) integration frameworks → action frameworks
The contents are not only readily available after filtration, but can also be operated upon. The key use case will be to morph the content from one type to another. Take the example of a bookmark, the bookmark can be changed into a discussion item and discussed in detail, or a clipping of an article can be altered into a new article.
3) Sorting out the information overload
The content integration brings data and information to you, and it’s hard to consume all of it. Strong filters and alerts based systems need to be developed to bring the most relevant information to you. This will also address the fear or missing out on things or skipping an essential piece of information or knowledge.
References
Albrighton, T.: Six problems with social search, 28.04.2011, http://econsultancy.com/uk/blog/7444-six-problems-with-social-search [28.04.2012]
AIIM, tcgAdvisors: A “Future History” of Content Management, p16
Back, A., Koch, M.: Broadening Participation in Knowledge Management in Enterprise 2.0. In: it – Information Technology, Vol. 53, Nr. 3 (2011) , p. 135-141.
Gillmore, S.: Rest in peace, RSS, 05.05.2009, http://techcrunch.com/2009/05/05/rest-in-peace-rss/ [28.04.2012]
Gorton, I.: Essential Software Architecture. Springer. Heidelberg 2006.
Hinchcliffe, D.: Moving beyond systems of record to systems of engagement, 08.06.2011, http://www.dachisgroup.com/2011/06/moving-beyond-systems-of-record-to-systems-of-engagement/ [28.04.2012].
Hohpe, G., Woolf, B.: Enterprise Integration Patterns: Designing, Building, and Deploying Messaging Solutions. Addison-Wesley Signature Series. Boston 2003
IBM: Application Integration::Federation application pattern::Runtime patterns, 20.10.2004, http://www.ibm.com/developerworks/patterns/application/at12-runtime.html [28.04.2012].
IdeoTechi: Introduction to JMS, 05.03.2012, http://idiotechie.com/?p=141 [28.04.2012].
→ Link to Message Oriented Middleware:
Lepofsky, A.: Making Activity Streams More Manageable, 03.02.2012, http://www.constellationrg.com/blog/2012/02/making-activity-streams-more-manageable [28.04.2012].
McAfee, A.: Enterprise 2.0: The Dawn of Emergent Collaboration. In: MITSloan Management Review 47(3), 2006.
Moore, G.: A Sea Change in Enterprise IT. Systems of Engagement and The Future of Enterprise IT. (AIIM Whitepaper), 2011, http://www.aiim.org/~/media/Files/AIIM%20White%20Papers/Systems-of-Engagement.pdf [28.04.2012].
Roth, C.: If You Thought Your Inbox Was Overloaded, Wait Until Activity Streams, 08.03.2011, http://blogs.gartner.com/craig-roth/2011/03/08/if-you-thought-your-inbox-was-overloaded-wait-until-activity-streams/ [28.04.2012].
→ Gartner
Suarez, L.: 5 Reasons why activity streams will save you from information overload, 04.05.2011, http://www.elsua.net/2011/05/04/5-reasons-why-activity-streams-will-save-you-from-information-overload/ [28.04.2012].
Zuckerberg, M. et al.: System and method for dynamically providing a news feed about a user of a social network. US 2008040673, 14.02.2008.
—–
Differences between transactional and engagement systems:
Our initial research identifies nine characteristics of engagement systems that differ from the transactional systems of yesteryear (see the table below for a historical view):
1. Design for sense and response. Engagement systems “listen” to assess status, sentiment, and context. For example, detection of negative sentiment could lead to a discount on your next purchase or a proactive phone call to address an issue. These systems go beyond transactional systems that focus on reliability, stability, and continuous improvement.
2. Address massive social scale. Engagement systems seek to master social networks. Social scale requires constant feedback from networks of people and objects. LinkedIn is an example of how we connect, collaborate, and share with each other in a career aligned social network. Transactional systems focus on addressing massive computing scale.
3. Foster conversation. Engagement systems support two-way conversations. Chat, video, and sharing features enable conversations among individuals, teams, and even machines. Transactional systems push one-way communications in a dictatorial approach
4. Utilise a multitude of media styles for user experience. Engagement systems embrace the multi-media, social-led user experience. Media channels include Twitter, video, text, and “likes.” Transactional systems limit themselves to machine based interfaces.
5. Deliver speed in real time. Engagement systems focus on real-time speed. Users can see activity streams, real-time alerts, and notifications on all their devices. Transactional systems aim for just-in-time delivery.
6. Reach to multi-channel networks. Engagement systems touch corporate, personal, and machine based networks. A Skype call or instant message reaches out to both the corporate directory and your own personal network. Transactional systems narrowly focus on departmental and corporate networks.
7. Factor in new types of information management. Engagement systems embrace loosely structured knowledge flows. Comments, audio files, videos, and chats don’t fit neatly into corporate relational tables. Transactional systems ensure reliability of highly structured records and data.
8. Apply a richer social orientation. Engagement systems by nature rely on heavy social orientation. The design natively incorporates social media tools such as RSS feeds, LinkedIn, Facebook, and Twitter. Transactional systems express a tangential or just plain awkward social orientation.
9. Rely on smarter intelligence. Engagement systems are powered by business rules and complex event processing engines. Users can change the flow of a task using visual tools. Transactional systems remain in a hard coded, rigid structured approach.
http://blogs.hbr.org/cs/2011/10/moving_from_transaction_to_eng.html
Terminology
Wiki page: http://p2pfoundation.net/Systems_of_Engagement
Overview by Ray: http://blogs.hbr.org/cs/2011/10/moving_from_transaction_to_eng.html
OPen Api, Open Graph protocol
even old and stale Intranets can be seen as system of records rather than system of engagements
Integration of:
- external social media channels (e.g. twitter streams)
- – systems of record → transaction: ERP, CRM, SCM (Supply Chain MAnagement)
- – systems of engagement –> interaction
- according to MOore: “social business systems designed to dramatically improve the productivity of middle tier knowledge workers. … (they) enhance the ability of knowledge workers to quickly cooperate with each other in order to improve operating flexibility and customer engagement.” → needs to be wider. it’s not just middle tier knowledge workers these days.
- make it easier for people to communicate with each other;
- digital social objects are editable, amendable, commentable, taggable. Archivable, searchable, findable.
- users can create and share data views, interacting with the information within them

Why Do Integration
Since the dawn of computing, each individual has had their own way of solving problems, hence various applications have been developed to meet specific needs. These organically developed applications work in isolation and are able to operate on specific contents to generate specific reports or outcomes.
Within organisations, there are different business units which need to communicate with each other to get the job done. As each of the business unit has their own favoured tool to manage their work, it is essential that information is able to flow between these information islands. Integration is the way to bridge the gap between these disparate applications or information islands.
AIIM: http://www.aiim.org/~/media/Files/AIIM%20White%20Papers/Systems-of-Engagement.pdf
JP’s thoughts on system of records and engagement: http://confusedofcalcutta.com/2011/02/23/social-objects-in-the-enterprise-some-early-thoughts/
——-
3.1 Linking and Embedding
Advantages
Linking allows a simple way to provide a central location to access multiple applications
It is easy to implement and manage
Disadvantages
There is no consistent navigation between applications
No centralised area of dashboard to view contents from multiple applications
Manual update of links (dead links)
no search
3.2 Widget approach
e.g. take the example of iGoogle, which allows contents of multiple types to be displayed on a single page. One can add a weather widget, a stock widget or a news widget on the same page. These widgets have contents which are completely un-related to each other and so do not communicate with each other.
The number of content items available within one widget can be altered by the widget specific configuration. e.g. one can display the last 5 items from a news source rather than the default 3 items set as default by the system.
1. Bridging internal and external conversations
The Web 2.0 enables everyone to participate in conversations. Some of these public conversations can be relevant and interesting to businesses. Organisations need to find ways to bridge their internal world with the external world and vice versa.
2. Discussing client opportunities
Customer Relationship Management systems (CRM) have been around for some time. However, often they are relegated to data stores, which are liked by managers but hated by users due to their complexity and the perceived limited value to them. It is important to integrate CRM data and to make it available in the right context where it can be seen and enhanced by others.
3. Current Awareness
Especially in knowledge intensive industries like professional services, it is critical for knowledge workers to keep abreast of developments in the market that could have an impact on clients. New applications like RSS feed management systems enable users to monitor hundreds of news sources. If this is done in a joined-up way, organizations could save lots of time and money. However, this requires the integration of such news tools with other applications.
4. Content collaboration
Regardless of the industry and the role, content collaboration is a critical activity in the knowledge economy. Content collaboration used to take place only in structured format (documents). These days unstructured format like wikis are proving more and more popular due to the shortcomings of document collaboration. However, applications need to be integrated into users’ workflows and hence into systems used on a daily basis, no matter where content collaboration takes place.


